想必有很多和我一样的人只有把喜欢的图片视频下载下来才能感觉到安心,下面分享一个e621网站的爬虫编写过程
首先看看关键词查询时url是如何构造的  这是直接关键词搜索的情况  这是分页查询的情况 url参数显然page代表页码,tags代表关键词/标签
然后再分析一下网站,现在首次进入会出现18+界面,刚开始以为需要进行认证才能获取页面(也就是伪造token)
不过通过分析源码发现,其实这个界面只是类似遮罩的效果,如果删除这个元素,其实是可以直接看到网页内容的,这个data-file-url就是我们要找的下载链接
这里我们可以通过正则表达式data-file-url="(?P<url>.*?)".*?\nID: (?P.*?)\n提取出图片的地址
众所周知,这种页面的图片肯定是循环堆砌相同元素呈现的,也就是只要用上面的正则匹配一下,就能获得这个页面的所有地址
代码如下: - # 获得页面中的文件信息
- # page_text 页面的文本内容
- def getPageDatas(page_text):
- files = []
- obj = re.compile(r'data-file-url="(?P<url>.*?)".*?\nID: (?P<id>.*?)\n', re.S)
- results = obj.finditer(page_text)
- for result in results:
- url = result.group("url")
- id = result.group("id")
- name = url.split('/')[-1]
- file = {
- "url": url,
- "id": id,
- "name": name
- }
- files.append(file)
- return files
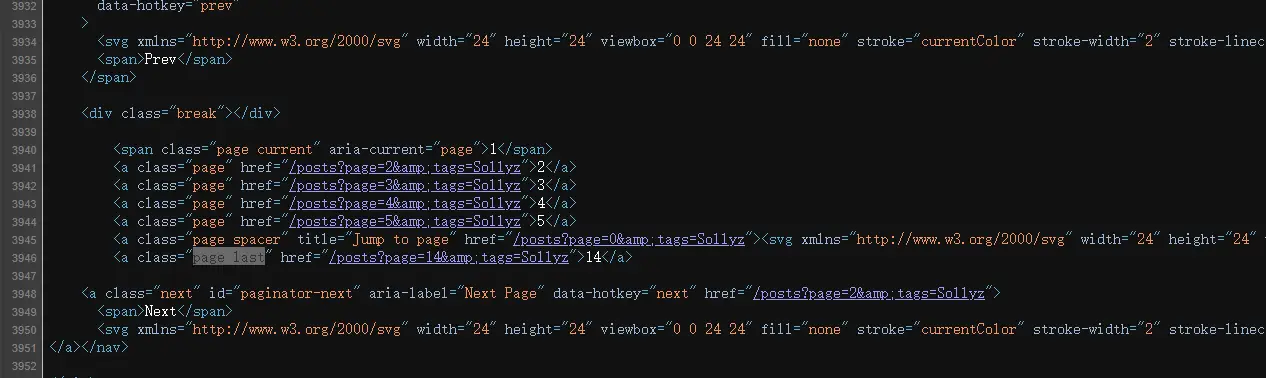
当然,某个关键词的图片不一定只有一页 所以我们需要找到所有页码,然后经过一番分析,也很容易找到class为last page的a标签内部文本就是页码长度,所以到时候请求的时候只需要进行14次分页请求,如果有想要尝试的可以去找找这段 这个文本应该如何提取呢,通过分析发现,在整个页面中,class="last page"只出现了一次,也就是说,使用bs4的find即可找到这个标签
代码如下: - # 获得页面数量
- # url 链接
- # headers 请求头
- # data 请求表单
- def getLastPage(url, headers, data):
- try:
- with requests.get(url=url, headers=headers, data=data) as resp:
- bs = BeautifulSoup(resp.content, "html.parser")
- a = bs.find(name="a", attrs={"class": "page last"})
- last_page = (int) (a.text)
- except IndexError:
- last_page = 1
- return last_page
既然网页已经分析完毕,下面可以编写整体自动爬取的代码了 - import re
- import requests
- from bs4 import BeautifulSoup
- # 获得页面数量
- # url 链接
- # headers 请求头
- # data 请求表单
- def getLastPage(url, headers, data):
- try:
- with requests.get(url=url, headers=headers, data=data) as resp:
- bs = BeautifulSoup(resp.content, "html.parser")
- a = bs.find(name="a", attrs={"class": "page last"})
- last_page = (int) (a.text)
- except IndexError:
- last_page = 1
- return last_page
- # 获得页面中的文件信息
- # page_text 页面的文本内容
- def getPageDatas(page_text):
- files = []
- obj = re.compile(r'data-file-url="(?P<url>.*?)".*?\nID: (?P<id>.*?)\n', re.S)
- results = obj.finditer(page_text)
- for result in results:
- url = result.group("url")
- id = result.group("id")
- name = url.split('/')[-1]
- file = {
- "url": url,
- "id": id,
- "name": name
- }
- files.append(file)
- return files
- # 获得下载的多线程任务数组,要await
- # keyword 搜素的关键词
- # path 下载路径
- def resolve(keyword, path):
- # 若关键词为空,返回空数组,防止请求到一堆数据
- if keyword == '':
- return []
- # 请求头
- headers = {
- "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Safari/537.36 Edg/104.0.1293.54"
- }
- # 链接
- url = "https://e621.net/posts?"
- # 表单
- data = {
- "page": 1,
- "tags": keyword
- }
- # 获得最后一页的页码
- lastPage = getLastPage(url=url, headers=headers, data=data)
- print("获取到总页数为{}".format(lastPage))
- # 获得页面文本
- print("目前正在处理:e621...")
- page_texts = []
- while data["page"] <= lastPage:
- print("正在抓取获取第" + str(data["page"]) + "个页面的内容")
- with requests.get(url=url, headers=headers, data=data) as resp:
- page_texts.append(resp.text)
- data["page"] += 1
- # 创建任务列表
- for page_text in page_texts:
- files = getPageDatas(page_text)
- i = 0
- for file in files:
- url = file["url"]
- with requests.get(url=url, headers=headers) as response:
- if response.status_code == 200:
- # 以二进制写入模式保存文件到本地
- with open('{}/{}-{}'.format(path, file["id"], file["name"]), 'wb') as file:
- file.write(response.content)
- i = i+1
- print("文件下载成功!")
- else:
- print("下载失败,状态码:", response.status_code)
- if __name__ == '__main__':
- resolve('Sollyz', 'C:\\Users\\14586\Desktop\\test')
当然我们知道,requests库是阻塞式的,当要下载的图片有成百上千个时,下载的等待时间甚至不如自己手动点击去下载,这时候就需要多线程出马了,于是我请ai老师帮我生成了一套使用场景是qt5且能够多线程进行的请求库: 并让他基于以上两套代码编写了对应的图形化界面爬虫代码
最终效果如图,如果重复下载的话会自动跳过这一条: 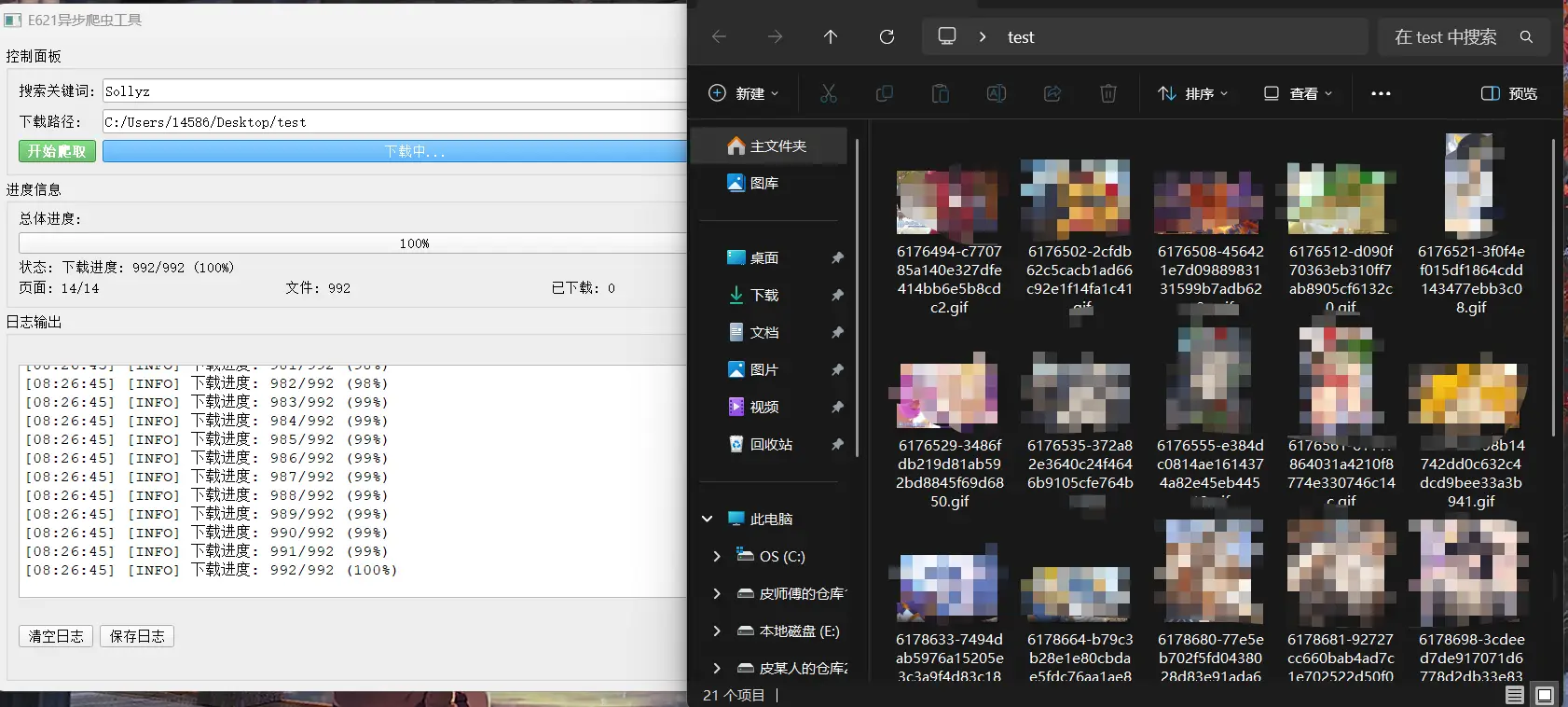
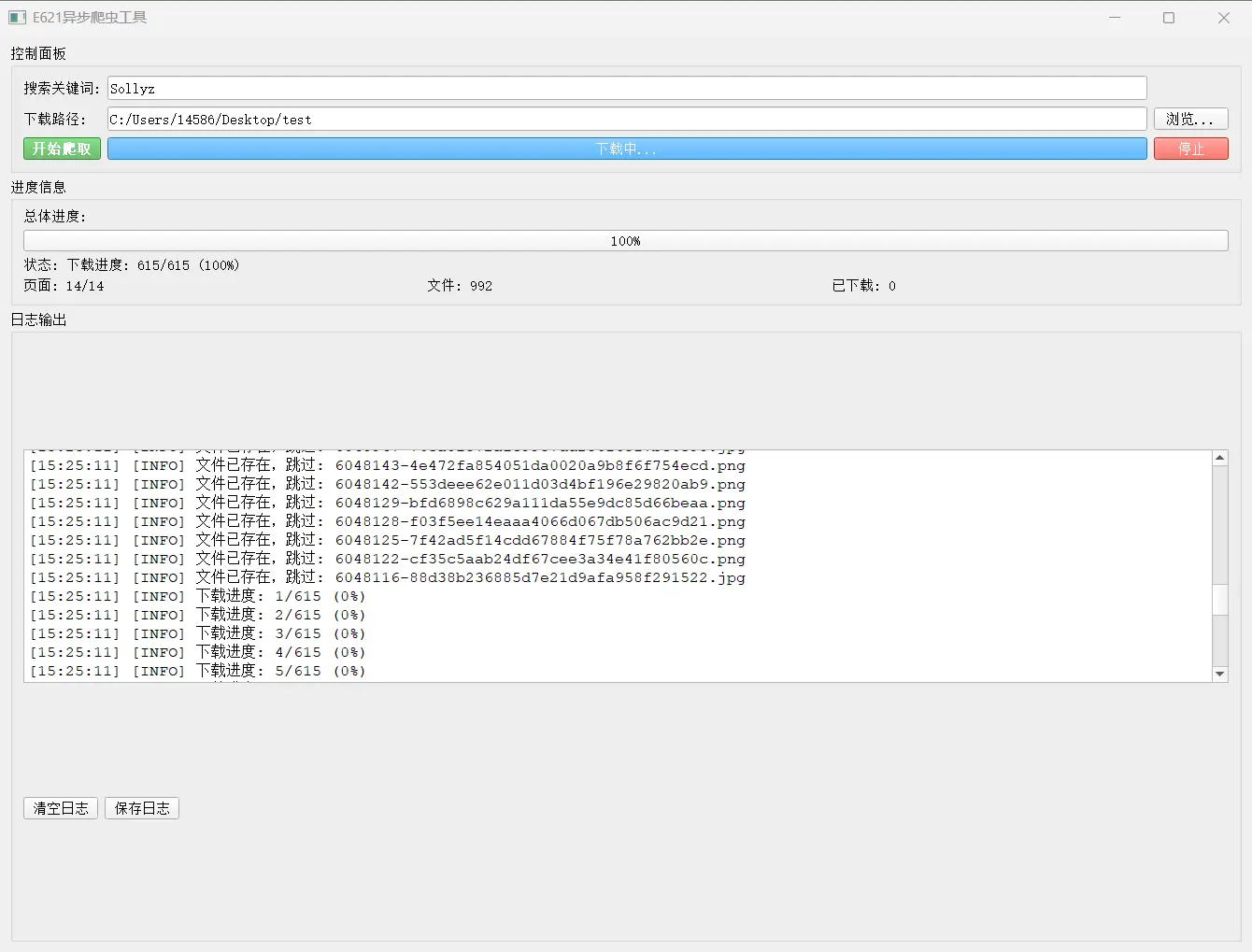
工具和本次爬取结果在附件,请查收 | 

 [复制链接]
|关注本帖
[复制链接]
|关注本帖

 /1
/1 
 GameMale
GameMale
 金币
金币 血液
血液 旅程
旅程 追随
追随 知识
知识 咒术
咒术 堕落
堕落 灵魂
灵魂 主题
主题 回帖
回帖 日志
日志 精华
精华 好友
好友 积分
积分

 楼主
楼主

 提升泵
提升泵 亮色刷
亮色刷 小时顶
小时顶






























![霉运小精灵[红]](https://img.gamemale.com/album/202606/09/023747o34vdyv28myyoxmo.gif)